| 基于PCA | 您所在的位置:网站首页 › 病虫害识别基于matlab gui svm病虫害识别系统含 › 基于PCA |
基于PCA
|
首先,让我们了解 PCA 和 SVM 是什么:主成分分析:主成分分析(PCA)是一种机器学习算法,广泛应用于探索性数据分析和建立预测模型,它通常用于降维,通过将每个数据点投影到前几个主成分上,以获得低维数据,同时尽可能保留数据的变化。 Matt Brems 的文章全面深入地介绍了该算法。现在,让我们用更简单的术语来理解算法:假设我们现在正在收集数据,我们的数据集产生了多个变量、多个特征,所有这些都会在不同方面影响结果。我们可能会选择删除某些特征,但这意味着会丢失信息。因此我们开源使用另一种减少特征数量(减少数据维数)的方法,通过提取重要信息并删除不重要的信息来创建新的特征,这样,我们的信息就不会丢失,但起到减少特征的作用,而我们模型的过拟合几率也会减少。支持向量机支持向量机(SVM)是一种用于两组分类问题的有监督机器学习模型,在为每个类别提供一组带标签的训练数据后,他们能够对新的测试数据进行分类。
Matt Brems 的文章全面深入地介绍了该算法。现在,让我们用更简单的术语来理解算法:假设我们现在正在收集数据,我们的数据集产生了多个变量、多个特征,所有这些都会在不同方面影响结果。我们可能会选择删除某些特征,但这意味着会丢失信息。因此我们开源使用另一种减少特征数量(减少数据维数)的方法,通过提取重要信息并删除不重要的信息来创建新的特征,这样,我们的信息就不会丢失,但起到减少特征的作用,而我们模型的过拟合几率也会减少。支持向量机支持向量机(SVM)是一种用于两组分类问题的有监督机器学习模型,在为每个类别提供一组带标签的训练数据后,他们能够对新的测试数据进行分类。
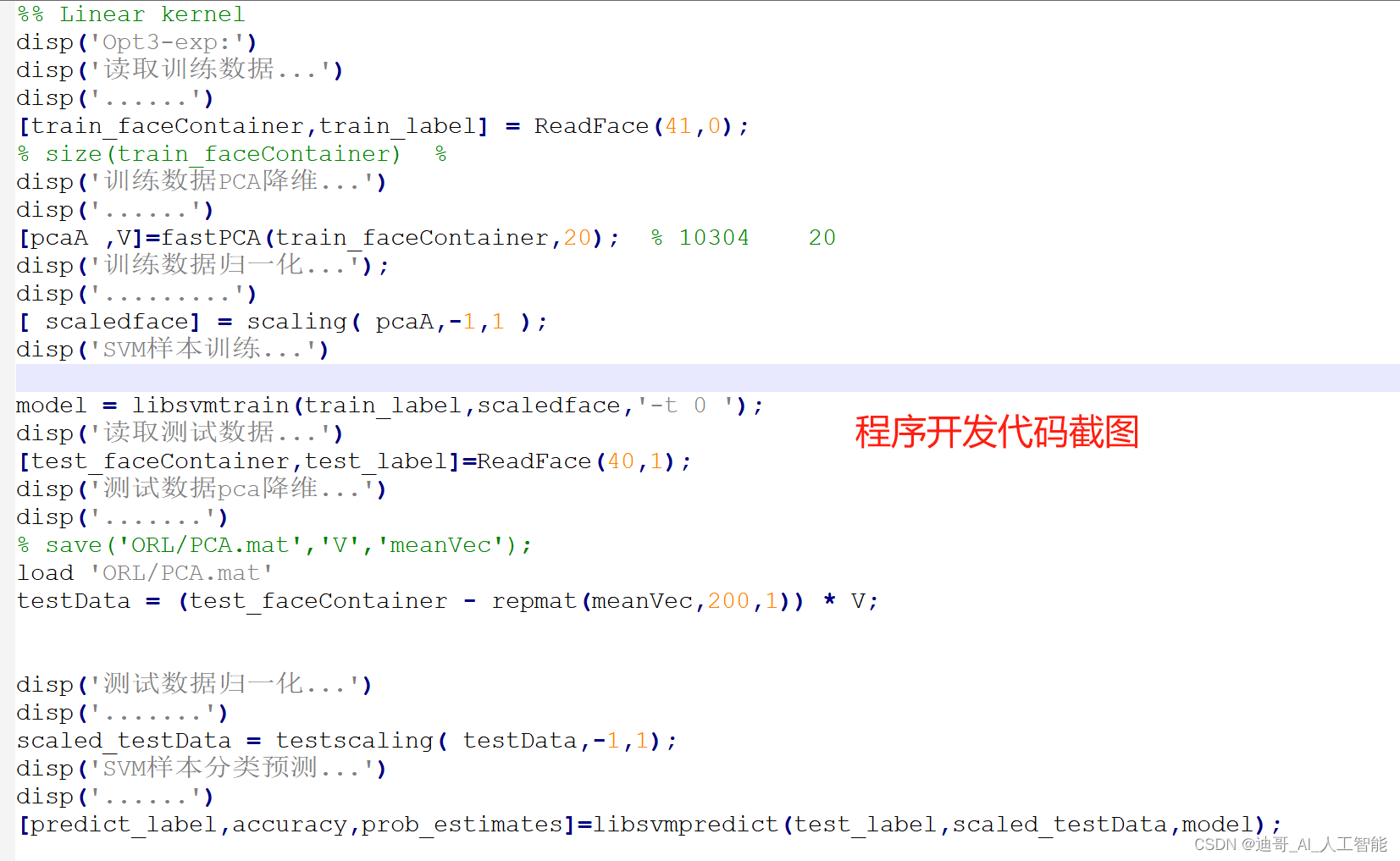
前期处理 使用PCA去除相关性;降维后的特征向量作为SVM分类的特征; 数据规格化 必要性:防止淹没数值较小的特征;防止内积过大导致溢出。 规格化的方法: 最大最小规格化; 零均值规格化 核函数的规格化 核函数 优先径向基核函数(RBF): RBF需要决定的两个参数,RBF核自身的参数η及错误代价系数C。 但是由于很难使用η和C来写成目标函数(识别率)表达式,我们采用LibSVM的基于交叉验证和网络搜索的参数选择方法。 备注简介此部分摘自互联网,仅供参考,若侵权,联系删除。 程序代码:
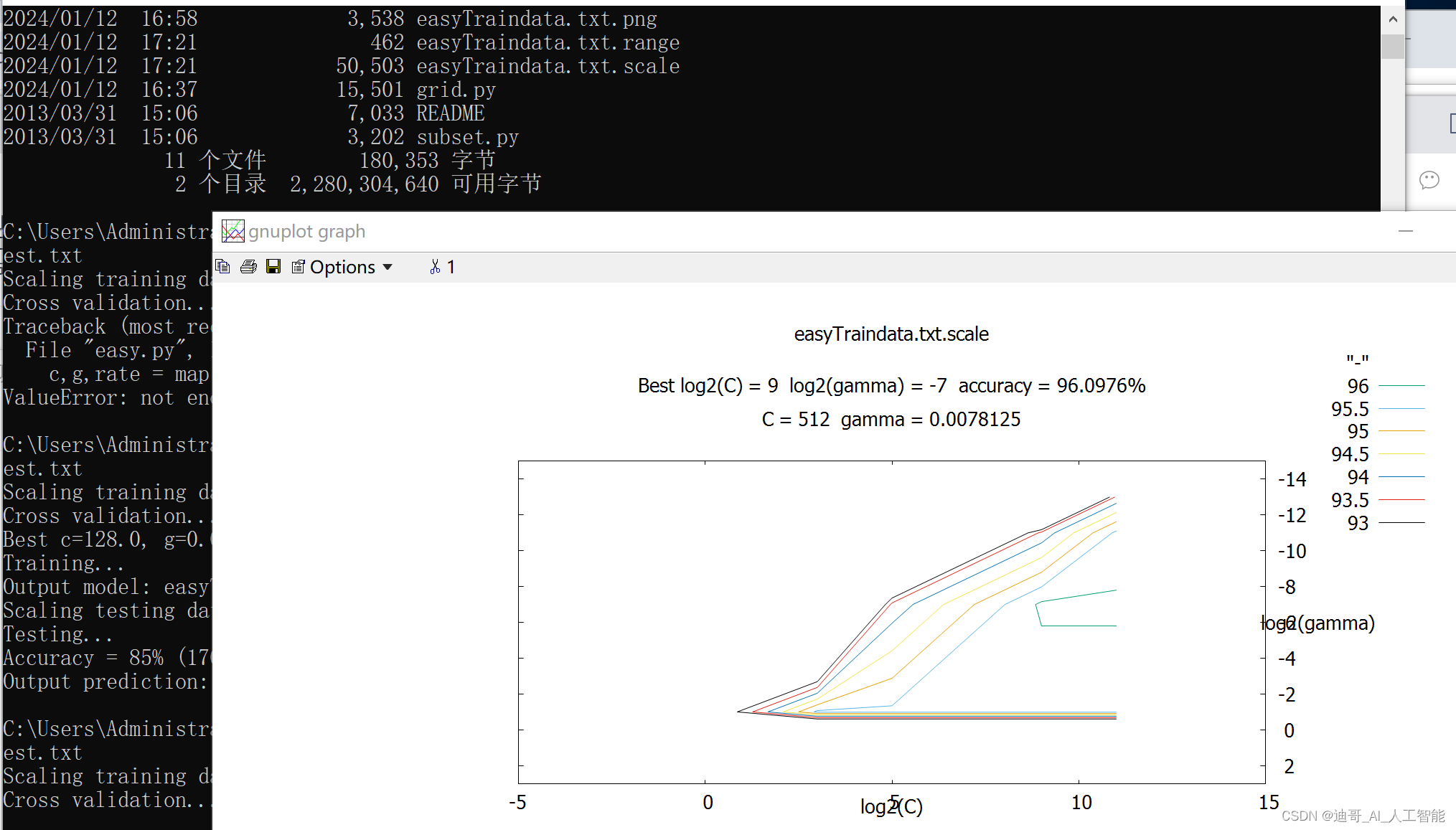
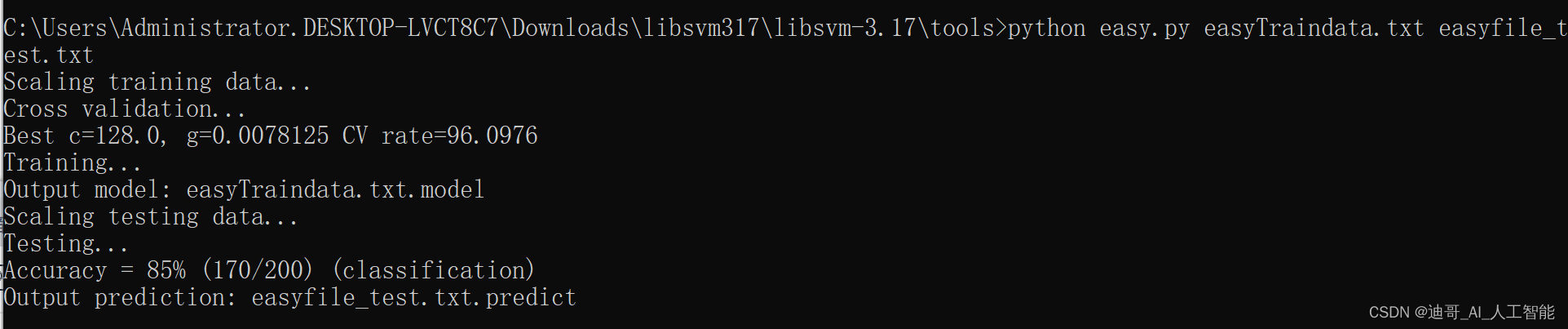
功能效果:
创作不易,相关程序,说明文档需求,如需要,可加作者新联系方式,WX:Q3101759565,QQ:3101759565[多加几次!!!]
祝您学业有成!工作顺利! 年薪百万! |


【本文地址】